

The Times Square service for publishing parameterized Jupyter Notebooks in the Rubin Science platform#
Abstract
The Times Square service publishes Jupyter Notebooks as webpages within the Rubin Science Platform (though outside JupyterLab). Authors of notebooks can parameterize text and code within the notebook’s source. Viewers of the notebook can select values for these parameters to view a notebook rendered on-demand in conjunction with the Noteburst notebook service. Times Square is intended to be used for publishing live dashboards and reports of observatory operations and data processing activities. This technical note covers the concept and design of Times Square.
Use cases for Times Square#
Jupyter Notebooks are effective for documenting an analysis or data reduction by combining prose, code, and graphical outputs. Editing a notebook is intuitive for a large number of people at Rubin Observatory, including engineerings and scientists. The Nublado (JupyterLab) service in the Rubin Science Platform makes its very easy to edit and execute by providing a web-based experience that doesn’t require any local software or data installation.
Sharing a notebook with colleagues is certainly possible, though not streamlined. Consider this sequence of steps required for viewing a notebook shared by a colleague:
Spawn a JupyterLab pod.
Either download the notebook from GitHub or find the notebook in a shared directory.
Open an execute the notebook.
This operation can take a few minutes.
The idea behind Times Square is to accelerate the process of viewing a shared notebook into a single, fast operation: opening a URL in a web browser. With this speed and simplicity, Times Square can support a range of dashboarding applications, such as plotting key statistics from a recent observing run.
To support a limited degree of customization, notebooks can be parameterized. This would allow a viewer to, for example, set the bounds on a database query. If a viewer needs more customization, they can always download the notebook into their own JupyterLab session for a fully interactive computing experience.
The key functionality of Times Square#
This section summarizes the key features of Times Square that affect the user experience:
Times Square maintains a database of Jupyter Notebooks. These notebooks can be stored as
ipynbfiles in a GitHub repository along with a sidecar YAML file that provides metadata (e.g. title and description) along with the schema for the parameterized variables.Jupyter Notebooks are parameterized with Jinja templating syntax. Both text and code cells can be templated so that either the prose or the computed results of the notebook are generated dynamically.
Each notebook is published to the web as its own path:
/<root>/<notebook slug>. When a user visits a page’s URL, Times Square returns an HTML rendering of the executed notebook. By requesting the bare path, the user sees a notebook rendered from default parameters. However, the user can also add a query string to the URL to see the notebook rendered with those parameters, e.g./<root>/<notebook slug>?myvar=42&greeting=hello+world.For users in a web browser, Times Square provides a wrapper around the HTML-rendered notebook. This wrapper provides a form interface for selecting notebook parameters, along with basic metadata and navigation elements. The interface also provides a link for downloading the ipynb file for further editing beyond the scope of the parameterization.
At its root URL,
/<root>/, Times Square displays an index of available notebooks.
Service architecture#
Times Square consists of a user-facing web front-end application along with back-end API and service. These are both deployed as a single Phalanx service to the Rubin Science Platform.
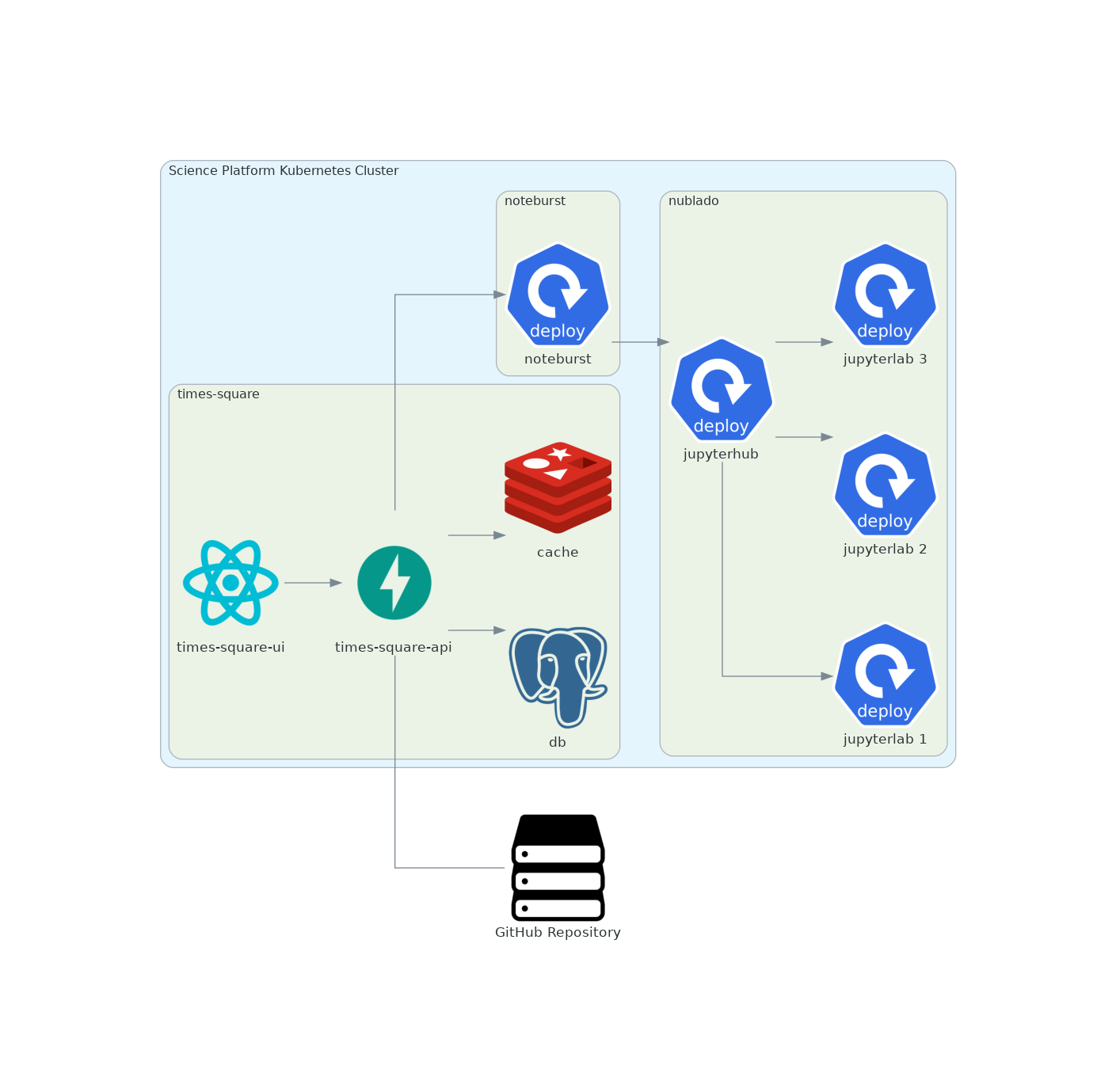
times-square-ui#
The UI is developed as a Next.js React application, following SQuaRE’s standard practice for a web application that has both server- and client-side code. The UI is deployed as a Kubernetes deployment.
The UI application’s server-side codebase is relatively simple, restricted primarily to dynamically configuring the UI at runtime for a given Rubin Science .
The UI has essentially type types of endpoints.
At the root endpoint, /root/, the UI displays a listing of available notebook pages based on data from the API service.
The notebook pages have endpoints /<root>/<notebook slug>.
The interface for these pages consist of an outer page wrapper, and an iframe consisting of the rendered HTML.
Rendering the notebook inside an iframe provides a number of advantages:
Since the
iframecontent is provided by an API service endpoint, Jupyter notebook rendering remains in a Python language service and thus the React front-end doesn’t need to renderipynbfiles, which can sometimes be challenging (see GitHub’sipynbpreview issues).The outer page wrapper can be rendered quickly, even if the notebook itself is still being rendered. This provides a better user experience than a delayed page load.
Changing the notebook parameters, and therefore fetching a new rendering of the notebook, does not result in a full page reload since only the
srcattribute on theiframechanges, again providing a smoother user experience.
Similar to the iframe, data for the outer page wrapper, including title and controls for changing notebook parameters, comes from the API service as well, though that data is rendered through React components onto the page.
times-square-api#
The API is developed as a FastAPI Python application, following SQuaRE’s standard practice for web services. The API service is generally responsible for the notebook domain:
maintaining a registry of notebooks
syncing notebooks from their source repositories
rendering templated notebooks and executing notebooks with Noteburst
providing rendered notebooks to the front-end service
The API service uses three external datastores: one or more GitHub repositories, a SQL database, and a Redis database.
The GitHub repositories are the ultimate sources for notebooks. Authors commit Jupyter Notebooks alongside metadata files into GitHub repositories. By registering as a GitHub App that is installed specifically into these source repositories, the times-square-api app can receive webook events whenever these notebooks are updated, and read the contents of updated notebooks even if the source repository is private. SQuaRE’s Semaphore notification services uses a similar pattern for sourcing broadcast messages from GitHub (SQR-060).
The SQL database stores the source notebooks, along with metadata from the sidecar metadata file. This data is updated through the GitHub App webhook events. To create a new “page” model row in the SQL database, an API user needs to specifically register the notebook and its source location in a GitHub repository. Part of this registration process is to claim the unique slug that the notebook will be served at.
The Redis database stores the products of notebook execution (both the rendered HTML and executed ipynb file).
These entries are keyed with a hash of the notebook slug, version, and parameters to ensure a unique and consistent cache look-up.
To cache database bloat, entries in Redis have a finite TTL so that they naturally expire from the database as the source notebook is updated or certain parameterizations become unused (e.g., a date in the past for a nightly dashboard).
When the API service receives a request for a notebook page, it first queries the Redis database.
If the executed notebook HTML and ipynb are not cached in Redis, the API service gets the current version of the notebook template from the SQL database, executes it via the Noteburst service, renders and returns the notebook HTML to the requester, and caches that notebook into Redis.
Summary of interfaces with other services#
The Noteburst service is responsible for executing the
ipynbfile. Times Square is responsible for preparing theipynbfile for Noteburst (rendering Jinja templating) and converting the executed Notebook into HTML. Note that Noteburst further delegates notebook execution to JupyterLab itself.When Times Square executes a notebook through Noteburst, it is responsible for specifying a JupyterLab user account (username and UID), or potentially a pool of users, to execute the notebooks with. Notebooks are not executed through normal user accounts (for example, the account of the notebook’s author). Ideally, Noteburst can maintain a running pool of JupyterLab pods, and route requests to those pods.
Gafaelfawr provides authentication and authorization for both the web front-end and the API services.
The Times Square RESTful API#
This section is an overview of the core RESTful API endpoints provided by the API service. These endpoints are used both by the front-end and any administrative API users.
GET /v1/repositoriesIterates over the GitHub repositories that the Times Square GitHub app is installed in, and summarizes the potential notebook pages found in each repository.
GET /v1/repositories/:org/:nameGet notebook pages published from a specific repository.
GET /v1/pagesIterates over all registered pages and includes metadata about the page. This endpoint can be used for the homepage UI.
POST /v1/pagesRegisters a new notebook page, corresponding to a template notebook found with the
GET /v1/repositoriesendpoint.GET /v1/pages/:slugGet the notebook page’s resource (primarily the notebook’s metadata; use the
GET /v1/pages/:slug/sourceendpoint to get the ipynb file).PATCH /v1/pages/:slugUpdate the notebook page’s resource.
DELETE /v1/pages/:slugDelete a notebook page.
GET /v1/pages/:slug/sourceGet the source
ipynbnotebook for a page (not the executed notebook).GET /v1/pages/:slug/html(?<parameters>)Get a rendered notebook HTML computed for either the default parameters (if no query string is provided) or specific parameters (if a query string is provided). If the computed notebook is available from the Redis cache, that version is provided. Otherwise this endpoint triggers a computation via Noteburst.
GET /v1/pages/:slug/rendered(?<parameters>)Get a rendered ipynb notebook computed for either the default parameters (if no query string is provided) or specific parameters (if a query string is provided). If the computed notebook is available from the Redis cache, that version is provided. Otherwise this endpoint triggers a computation via Noteburst.